ご利用ガイド Hadoopアプリケーションを使う
目次
Hadoopは、巨大なデータを複数のコンピュータで分散処理・集計することで高速に実行するフレームワークです。
ConoHaではHadoopの中でも分散ファイルシステムであるHDFSと分散処理基盤となるMapReduce 2.0(YARN)をインストール済みのアプリケーションイメージを提供していますので、すぐに使い始めることが出来ます。
Hadoopは「Slaveノードを管理するMasterノード」と複数の「データを貯蔵したり実際に計算処理を行うSlaveノード」による1対多の複数台構成となっています。ここではMasterノード1台、Slaveノード3台(HDFSの設定の関係上最低3台必要です)構成のHadoopクラスタを構築してみます。
※こちらのアプリケーションイメージは現在提供を終了しております。提供終了以前にサーバー構築されているVPSにおきましてはイメージ保存を利用してサーバー再構築も可能でございますので、下記初期設定をご確認ください。
HadoopのMasterノード作成方法
[1] 「サーバー追加」ボタンをクリックします。
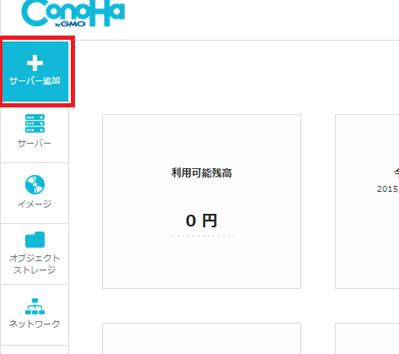
[2] イメージタイプ:アプリケーション→アプリケーション:Hadoop→バージョン:master node-2.6-64bitの順に選択し、VPSを作成します。
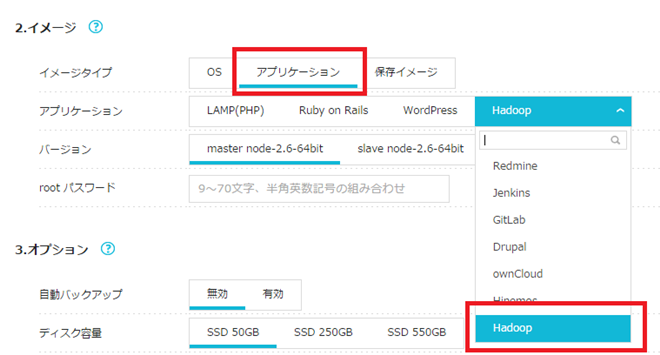
Hadoopクラスタは複数台のVPSを使用しますので、どのVPSがどの役割を持っているのかを把握するためにネームタグを設定することをお勧めします。
[3] VPSが起動したら、SSHで接続します。
Slaveノードの作成方法
HadoopではSlaveノードの数が処理能力に直結していますから、処理能力が必要な場合にはSlaveノードを大量に用意する必要があります。プログラムの動作確認のような小規模な用途でも3~5ノードで構築されますし、本番環境では数十単位のノードで構築する場合があります。これだけのVPS追加を手作業で繰り返すのは手間ですが、ConoHaではVPSの追加・削除もできるAPIを提供していますのでこれを利用して半自動化してしまいましょう。
[1]ConoHaのAPIを実行するシェルスクリプトをダウンロードします
ConoHaのAPIを使用してVPS作成を自動化したシェルスクリプトをご用意しています。こちらからダウンロードしてMasterノードに保存してください。
このシェルスクリプト自体は東京リージョンにのみ対応しています。シンガポールやサンノゼリージョンで実行したい場合にはAPIのエンドポイントURIやイメージUUID、flavorのUUIDをそのリージョンのものに併せて変更する必要があります。
[2]このスクリプトに実行権限を付与します
以下のコマンドを実行してください。
chmod +x create_newslavenode.sh[3]このスクリプトの実行に必要なプログラムをインストールします
このシェルスクリプトではJSON読み込むために、jqというプログラムを使用しています。
標準ではインストールされていませんので、以下のコマンドからインストールしてください
yum install -y jq[4]実行するために必要な情報を集めます
このスクリプトを実行するには(=APIを使用するには)、お客様ごとに設定されるAPIユーザー名・APIパスワード・テナントIDが必要になります。
これらの情報の集め方は「APIを使用するためのトークンを取得する」の[1]~[4]をご覧ください
[5]スクリプトを実行します
※このスクリプトを実行すると実際にVPSが作成され、作成したVPSのプラン・作成した台数・VPSが存在していた期間によってご利用料金が発生します **
以下のコマンドを適宜書き換え、実行します。
./create_newshalvenode.sh [APIユーザー名] [APIパスワード] [テナントID] [VPSのプラン] [作成するSlaveノードの数] [設定したいrootパスワード]今回はVPSのプランは1GB,作成するSlaveノードの数は3台(構成可能な最低構成)としますので以下のようになります。

実行が正常に終了すればコントロールパネルにも作成したVPSが表示されます。

作成するSlaveノードの数にもよりますが、実行に数分かかる場合があります。
また、このスクリプトの実行が完了しVPSの作成が完了しても、その中のOSはまだ起動処理中の可能性がありますので、そのまましばらくお待ちください。
正常に終了すると、同じディレクトリ内にhostsとinventoryというテキストファイルが生成されます。
以上でSlaveノードの作成は完了です。
Hadoopクラスタの構築方法
以下すべてMasterノードのVPSに接続したSSHでの作業です。
[1] 作成したSlaveノードに対して、Masterノードからホスト名でアクセスできるように設定します
先ほど生成されたhostsファイルを/etc/hostsの末尾に追記します。
以下のコマンドを実行してください。
cat ./hosts >> /etc/hosts[2] 複数あるSlaveノードを一括して設定を操作するために構成管理ツールを使用する準備をします
構成管理ツールとしてAnsibleがインストール済みとなっていますので、これを使用します。
まずはどのコンピュータを一括設定の対象とするかをAnsibleに教える必要があります。
inventoryファイルを/root/setup-slavenode/slavenodesの末尾に追記します。
以下のコマンドを実行してください。
cat ./inventory >> /root/setup-slavenode/slavenodes[3] Ansibleを実行します
/root/setup-slavenodeディレクトリに移動し、以下のコマンドを実行してください。
ansible-playbook -i slavenodes setup_slavenode.yml --ask-passSSH接続するためのパスワードを入力すると、実際にAnsibleのタスクが実行され数々の設定が反映されていきます。
[4]いったんすべてのノードを再起動します
Slaveノードを1つ1つ再起動するのは面倒ですから、ここでもAnsibleを使用します。以下のコマンドを実行するとslavenodesファイルに登録されているコンピュータはすべて再起動されます。
ansible -i slavenodes conohadoop-slavenodes -m command -a "shutdown -r now" --ask-passMasterノードも再起動しましょう
shutdown -r nowここまででSlaveノードに関する設定はすべて完了です。あとはMasterノードでのデーモン起動だけです。
[5]HDFSをフォーマットします
Masterノードで以下のコマンドを実行してください。
sudo -u hdfs hdfs namenode -format[6]HDFSを起動します
Masterノードで以下のコマンドを実行してください。
chkconfig hadoop-hdfs-namenode onservice hadoop-hdfs-namenode start[7]YARNを起動します
Masterノードで以下のコマンドを実行してください。
servcie hadoop-yarn-resourcemanager startchkconfig hadoop-yarn-resourcemanager on上記コマンドの実行後、下記のコマンドを実行するとMasterノードのYARNが管理しているSlaveノードが一覧表示されます。
yarn node -list
もし表示されない場合にはSlaveノードのnodemanagerを再起動(下記コマンド)し、もう一度試してみてください。
ansible -i slavenodes conohadoop-slavenodes -m command -a "service hadoop-yarn-nodemanager restart"[8]HistoryServerを起動します
Masterノードで以下のコマンドを実行してください。
sudo -u hdfs hadoop fs -mkdir -p /mr-history/{done,tmp}service hadoop-mapreduce-historyserver start chkconfig hadoop-mapreduce-historyserver on[9]Hadoopクラスタの完成です。サンプルプログラムを実行してみましょう
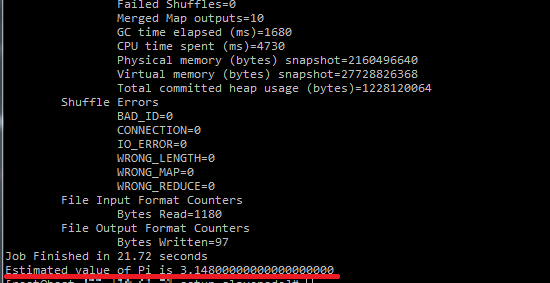
Hadoopに付属のサンプルプログラムにモンテカルロ法による円周率の計算があります。
データを準備する必要がないので手軽に実行できるうえ、Hadoopクラスタによるスケールアウト効果と計算した結果の意味がわかりやすいのでサンプルとして最適です。
Masterノードで以下のコマンドを実行してください。
sudo -u hdfs hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 10030秒程度でプログラムが終了し、円周率(に近い値)が表示されていますね。
最後に
Hadoopの良いところはSlaveノードを増やすとその分処理速度が向上する(ことが多い)ところです。
ConoHaのHadoopイメージでは手軽にSlaveノードを追加できますし、時間課金ですからコストはVPSの稼働時間ぶんだけです。
何か大量の計算をすることがあるときはぜひ使ってみてください。
HadoopやMapReduceの詳細については公式のドキュメントをご覧ください。
- 問題は解決できましたか?
-
お役立ち情報
ConoHaではサポートコンテンツの他にも以下のようなお役立ち情報をご用意しております。ぜひご活用ください。




